|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 |
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Basic Commands and Statistics with R rm(list = ls(all = TRUE)) getwd() #system("ls") setwd("~/ownCloud/STA_Statistics/basicR/") search() options(scipen=100) # scientific off options(scipen=0) # scientific on options(digits = 3) # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # https://stat.ethz.ch/R-manual/R-patched/library/datasets/html/mtcars.html attach(mtcars) search() detach(mtcars) search() mtcars # The data was extracted from the 1974 Motor Trend US magazine # ?mtcars class(mtcars) # determine the class of an object str(mtcars) # Compactly display the internal structure of an R object # 'data.frame': 32 obs. of 11 variables: # mpg cyl disp hp drat wt qsec vs am gear carb # Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 # Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 # Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 # Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 # Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 # Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 # Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 # Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 # Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 # Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 # Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 # Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 # Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 # Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3 # Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4 # Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4 # Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4 # Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 # Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 # Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 # Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1 # Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2 # AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2 # Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4 # Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2 # Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 # Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 # Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 # Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 # Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 # Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 # Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2 # A data frame with 32 observations on 11 (numeric) variables. #[, 1] mpg Miles/(US) gallon #[, 2] cyl Number of cylinders #[, 3] disp Displacement (cu.in.) #[, 4] hp Gross horsepower #[, 5] drat Rear axle ratio #[, 6] wt Weight (1000 lbs) #[, 7] qsec 1/4 mile time #[, 8] vs Engine (0 = V-shaped, 1 = straight) #[, 9] am Transmission (0 = automatic, 1 = manual) #[,10] gear Number of forward gears #[,11] carb Number of carburetors colnames(mtcars) <- c("mpg","cyl","disp","hp","drat","wt", "qsec","vs","am","gear","carb") # colnames(mtcars) <- c("miles-per-gallon","cylinders","displacement", # "horsepower","rear-axle-ratio","weight","qsec", # "engine-vs","Transmissionam","gear","carburetors") # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # data structures letters l <- letters str(l) # chr [1:26] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" # "q" "r" "s" "t" "u" "v" "w" "x" "y" "z" # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Vectors t <- c(1:3,"Hello",NA,FALSE,TRUE) t # [1] "1" "2" "3" "Hello" NA "FALSE" "TRUE" str(t) # chr [1:7] "1" "2" "3" "Hello" NA "FALSE" "TRUE" # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Factors mtcars$am[mtcars$am==1] which(mtcars$am==1) am.names <- mtcars$am am.names[which(am.names==1)] <- "Automatic" am.names am.names[which(am.names==0)] <- "Manual" am.names am.names.factor <- factor(am.names) am.names.factor # [1] Automatic Automatic Automatic Manual Manual # Levels: Automatic Manual # internally stored as a table of: # 1 Automatic # 2 Manual # Automatic and Manual are the levels of the factor levels(am.names.factor) relevel(am.names.factor, ref="Manual") # [1] Automatic Automatic Automatic Manual Manual # Levels: Manual Automatic am.names.factor[1] as.character(am.names.factor[1]) as.numeric(am.names.factor[1]) # numeric takes the faktor not the level levels(am.names.factor)[1] # can be used to get the factor table(am.names.factor) is.factor(am.names.factor) # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Data Frames mtcars str(mtcars) # 'data.frame': 32 obs. of 11 variables: df <- data.frame(1:20,60:41,letters[1:20]) df colnames(df) <- c("n1","n2","letters") df t(df) df$letters # get the vectors from the dataframe df$n1 df[,2] df[1,3] df[[3]] levels(df$letters) is.factor(df[,3]) df <- data.frame(1:20,60:41,letters[1:20], stringsAsFactors = FALSE) df is.factor(df[,3]) trees mtcars USMortality data() # list of data associated with all current packages in the serch path # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Matrix as.matrix(mtcars) mtcars.mat <- as.matrix(mtcars) # all elements of a matrix have the same mode #(numeric, character) x <- as.vector(mtcars.mat) # all in order in the vector X x mat <- matrix(1:100,nco=10) mat as.vector(mat) mat44 <- matrix(1:(4*4),nco=4) mat44 as.vector(mat44) dimnames(mtcars.mat) # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Arrays x <- 1:10000 # this is a matrix dim(x) <- c(100,100) x x <- 1:1000 # array - a matrix with more than 2 dim dim(x) <- c(10,10,10) x x <- 1:(2*3*3) # array - a matrix with more than 2 dim dim(x) <- c(2,3,3) x str(x) # int [1:2, 1:3, 1:3] 1 2 3 4 5 6 7 8 9 10 ... x <- letters[1:(2*3*3)] # array - a matrix with more than 2 dim dim(x) <- c(2,3,3) x str(x) # chr [1:2, 1:3, 1:3] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" # "m" "n" "o" "p" "q" "r" # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Lists - collect different types of data objects data() l <- list(mtcars,barley,environmental,ethanol,melanoma) # most data from lattice package str(l) # List of 5 # $ :'data.frame': 32 obs. of 11 variables: # ..$ mpg : num [1:32] 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ... # ..$ cyl : num [1:32] 6 6 4 6 8 6 8 4 4 6 ... # ..$ disp: num [1:32] 160 160 108 258 360 ... # ..$ hp : num [1:32] 110 110 93 110 175 105 245 62 95 123 ... # ..$ drat: num [1:32] 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ... # ..$ wt : num [1:32] 2.62 2.88 2.32 3.21 3.44 ... # ..$ qsec: num [1:32] 16.5 17 18.6 19.4 17 ... # ..$ vs : num [1:32] 0 0 1 1 0 1 0 1 1 1 ... # ..$ am : num [1:32] 1 1 1 0 0 0 0 0 0 0 ... # ..$ gear: num [1:32] 4 4 4 3 3 3 3 4 4 4 ... # ..$ carb: num [1:32] 4 4 1 1 2 1 4 2 2 4 ... # $ :'data.frame': 120 obs. of 4 variables: # ..$ yield : num [1:120] 27 48.9 27.4 39.9 33 ... # ..$ variety: Factor w/10 levels "Svansota","No.462",..: 3 3 3 3 3 3 7 7 7 7... # ..$ year : Factor w/2 levels "1932","1931": 2 2 2 2 2 2 2 2 2 2... # ..$ site : Factor w/6 levels "Grand Rapids",..: 3 6 4 5 1 2 3 6 4 5... # $ :'data.frame': 111 obs. of 4 variables: # ..$ ozone : num [1:111] 41 36 12 18 23 19 8 16 11 14 ... # ..$ radiation : num [1:111] 190 118 149 313 299 99 19 256 290 274 ... # ..$ temperature: num [1:111] 67 72 74 62 65 59 61 69 66 68 ... # ..$ wind : num [1:111] 7.4 8 12.6 11.5 8.6 13.8 20.1 9.7 9.2 10.9 ... # $ :'data.frame': 88 obs. of 3 variables: # ..$ NOx: num [1:88] 3.74 2.29 1.5 2.88 0.76 ... # ..$ C : num [1:88] 12 12 12 12 12 9 9 9 12 12 ... # ..$ E : num [1:88] 0.907 0.761 1.108 1.016 1.189 ... # $ :'data.frame': 37 obs. of 2 variables: # ..$ year : num [1:37] 1936 1937 1938 1939 1940 ... # ..$ incidence: num [1:37] 0.9 0.8 0.8 1.3 1.4 1.2 1.7 1.8 1.6 1.5 ... l[[1]] l[[2]] l[[3]] l[[1]] model <- lm(mpg~wt,data=l[[1]]) # building a model from a list object names(model) str(model) # the model itselfe is returned as a list model$coefficients model[[1]] # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # some basic R functions mtcars$mpg # [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 ... mtcars$mpg^2 # [1] 441.00 441.00 519.84 457.96 349.69 327.61 204.49 595.36 519.84 ... sqrt(mtcars$mpg^2) # [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 ... pi # [1] 3.141593 90*pi/180 # radiant conversion sin(90*pi/180) cos(90*pi/180) cos(0*pi/180) celsius <- 20 9/5*celsius+32 celsius <- -20:40 fahrenheit <- 9/5*celsius+32 plot(celsius,fahrenheit,type="s") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # sum(mtcars$mpg) # [1] 642.9 cumsum(mtcars$mpg) # [1] 21.0 42.0 64.8 86.2 104.9 123.0 137.3 161.7 cumprod(mtcars$mpg) # [1] 2.100000e+01 4.410000e+02 1.005480e+04 2.151727e+05 # 4.023730e+06 7.282951e+07 c(1,2,3,4,5) # vectors # concatenating function c(1:5) c(TRUE,FALSE) c("TRUE","FALSE") # character vector x <- runif(5) x # [1] 0.832 0.101 0.926 0.253 0.619 sort(x) order(x) # [1] 0.101 0.253 0.619 0.832 0.926 x[order(x)] # [1] 0.101 0.253 0.619 0.832 0.926 x <- c(1:5) x y <- c("TRUE","FALSE",NA) y z <- c(x,y) z # [1] "1" "2" "3" "4" "5" "TRUE" "FALSE" NA rev(z) # [1] NA "FALSE" "TRUE" "5" "4" "3" "2" "1" z[2] z[2:5] # [1] "2" "3" "4" "5" z[z<4] # [1] "1" "2" "3" NA z[z>4] # [1] "5" "TRUE" "FALSE" NA z[z>=4] # [1] "4" "5" "TRUE" "FALSE" NA z[-c(3,4)] # [1] "1" "2" "5" "TRUE" "FALSE" NA z[c(3,4)] # [1] "3" "4" z[is.na(z)] z[is.na(z)]<-0 z z[z==TRUE]<-1 z[z==FALSE]<-0 z # [1] "1" "2" "3" "4" "5" "1" "0" "0" plot(z) plot(z,type="b") x <- runif(length(z))*5 plot(x,z,type="b") plot(x~z,type="b") plot(z,x,type="b") lines(z~x,type="b",col="red") plot(sin((1:360)*pi/180),type="l") plot(sin((1:360)*pi/180),cos((1:360)*pi/180),type="l") plot(sin((1:360)*pi/18),cos((1:360)*pi/10),type="l") plot(sin((1:360)*pi/18),cos((1:360)*pi/10),type="l") plot(tan((1:360)*pi/180),cos((1:360)*pi/180),type="l") plot(tan((1:360)*pi/180),sin((1:360)*pi/180),type="l") |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 |
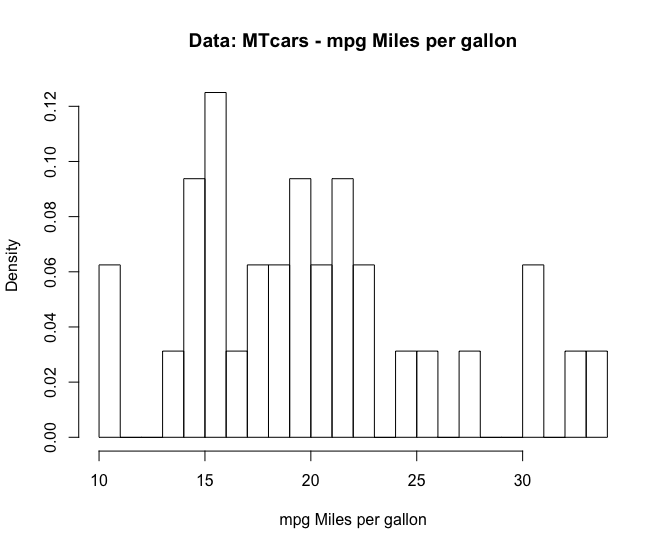
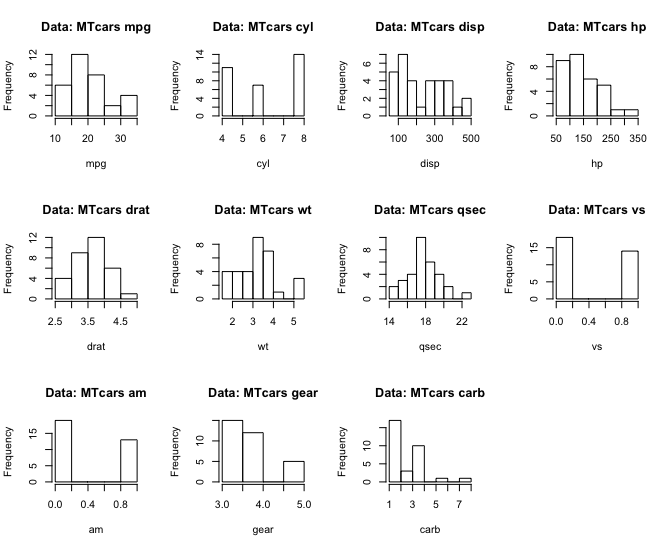
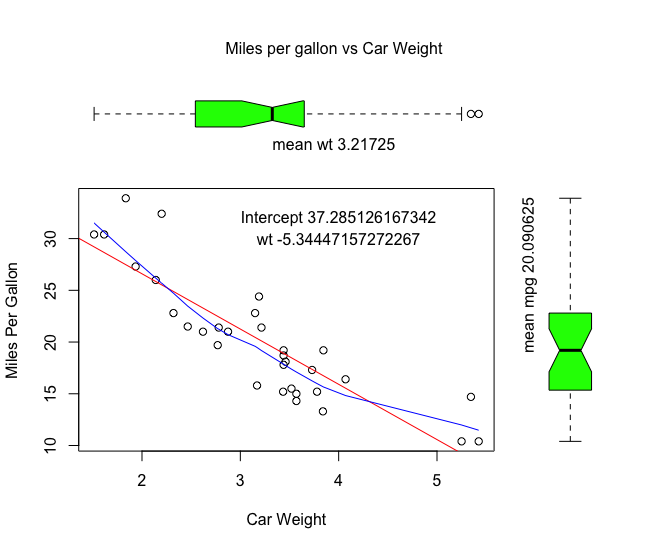
# - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # some loops for(i in 1:360){ plot(cos((1:360)*pi/i),sin((1:360)*pi/i),type="l") print(i) Sys.sleep(0.1) } for(i in 360:1){ plot(cos((1:360)*pi/i),sin((1:360)*pi/i),type="l") print(i) Sys.sleep(0.1) } for(i in 1:360){ for(e in 1:360){ plot(cos((1:360)*pi/i),sin((1:360)*pi/e),type="l") print(i) Sys.sleep(0.1) } } for(i in 1:360){ for(e in 1:360){ plot(sin((1:360)*pi/i),cos((1:360)*pi/e),type="l") print(i) Sys.sleep(0.1) } } for(i in 1:10){ for(e in 1:10){ plot(sin((1:360)*pi/i),cos((1:360)*pi/e),type="l") mtext(paste("i:",i,"e:",e), side=3, outer=TRUE, line=-3) print(paste("i:",i,"e:",e)) Sys.sleep(0.1) } } # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # function collection letters # "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" # "s" "t" "u" "v" "w" "x" "y" "z" LETTERS # "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" # "S" "T" "U" "V" "W" "X" "Y" "Z" letters[1:15] # [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" plot(mtcars$mpg) print(mtcars$mpg) table(mtcars$mpg) table(mtcars$cyl) # 4 6 8 # 11 7 14 table(mtcars[,9:10]) str(table(mtcars[,9:10])) # table with 2 dimmensions table(mtcars[,9:11]) str(table(mtcars[,9:11])) # 'table' int [1:2, 1:3, 1:6] 3 0 0 4 0 0 4 0 2 2 ... # - attr(*, "dimnames")=List of 3 # ..$ am : chr [1:2] "0" "1" # ..$ gear: chr [1:3] "3" "4" "5" # ..$ carb: chr [1:6] "1" "2" "3" "4" ... length(mtcars$mpg) cat(mtcars$mpg) mean(mtcars$mpg) median(mtcars$mpg) range(mtcars$mpg) unique(mtcars$mpg) rep(mtcars$mpg,10) names() colnames() rownames() diff(mtcars$mpg) plot(diff(mtcars$mpg),type="h",xlab="",ylab="difference") points(diff(mtcars$mpg),col="red") sort(mtcars$mpg) order(mtcars$mpg) rev(mtcars$mpg) rev(sort(mtcars$mpg)) cumsum(mtcars$mpg) cumprod(mtcars$mpg) rank(mtcars$vs) # Returns the sample ranks of the values in a vector. (r1 <- rank(x1 <- c(3, 1, 4, 15, 92))) rank(mtcars$vs, ties.method= "first") # first occurrence wins ## ranks without averaging rank(mtcars$vs, ties.method= "last") # last occurrence wins ## ranks without averaging rank(mtcars$vs, ties.method= "random") # ties broken at random ## ranks without averaging rank(mtcars$vs, ties.method= "random") # and again ## ranks without averaging 1:10 7:20 intersect(1:10, 7:20) match(1:10,7:20) # match returns a vector of the positions of (first) # matches of its first argument in its second. 1:10 %in% c(1,3,5,9) sstr <- c("c","ab","B","bba","c",NA,"@","bla","a","Ba","%") sstr %in% c(letters, LETTERS) sstr[sstr %in% c(letters, LETTERS)] apply() sapply() aggregate() aggregate(state.x77, list(Region = state.region), mean) tapply() merge(mtcars$vs,c(1,2)) read.csv() read.table() # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # histograms hist(mtcars$mpg) # looping with R par(mfrow=c(3,4)) for(i in 1:length(mtcars[1,])){ hist(mtcars[,i],main=paste("Data: MTcars",colnames(mtcars)[i]), xlab=paste(colnames(mtcars)[i])) } par(mfrow=c(1,1)) hist(mtcars$mpg, main="Data: MTcars - mpg Miles per gallon", xlab="mpg Miles per gallon") hist(mtcars$mpg, breaks=10, main="Data: MTcars - mpg Miles per gallon", xlab="mpg Miles per gallon") hist(mtcars$mpg, breaks=length(mtcars$mpg), main="Data: MTcars - mpg Miles per gallon", xlab="mpg Miles per gallon") # probability densities, component hist(mtcars$mpg, breaks=length(mtcars$mpg), freq=FALSE, main="Data: MTcars - mpg Miles per gallon", xlab="mpg Miles per gallon") # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # # Boxplot with Scatterplot par( fig = c( 0, 0.8, 0, 0.8 ), new = TRUE) plot( mtcars$wt, mtcars$mpg, xlab = "Car Weight", ylab = "Miles Per Gallon" ) abline( lm( mpg~wt ), col = "red" ) # regression line (y~x) lines( lowess( wt, mpg ), col = "blue" ) # lowess line (x,y) # LOWESS smoother which uses # locally-weighted # polynomial regression model <- lm( mpg~wt ) text( 4, 32, paste( "Intercept", model$coefficients[1] ) ) text( 4, 30, paste( "wt", model$coefficients[2] ) ) par( fig = c( 0, 0.8, 0.55, 1 ), new = TRUE ) boxplot(mtcars$wt, horizontal = TRUE, axes=FALSE, col= "green", notch = TRUE ) m.wt <- mean( mtcars$wt ) mtext( paste( "mean wt", m.wt ), side = 3, outer = TRUE, line = -8 ) par( fig = c( 0.65, 1, 0, 0.8 ), new = TRUE) boxplot( mtcars$mpg, axes = FALSE, col = "green", notch = TRUE) m.mpg <- mean( mtcars$mpg ) mtext( paste( "mean mpg", m.mpg ), side = 2, outer = TRUE, line = -28) mtext( "Miles per gallon vs Car Weight", side = 3, outer = TRUE, line = -3 ) par( mfrow = c( 1, 1 ) ) |
|
1 2 3 4 |
# Martin Stoppacher # # office@martinstoppacher.com # # - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - # ################################################################################# |
# – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – #
# Basic Commands and Statistics with R – 1
# path:
# file_name:
# files_used:
library() # shows a list of all installed packages with a short description
library( datasets )
?datasets
library( help = “datasets” ) # Information für Paket ‘datasets’
datasets::ability.cov
datasets::airmiles
datasets::AirPassengers
datasets::airquality
datasets::anscombe
datasets::attenu
datasets::WWWusage
# – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – #
# Available Datasets
# library(help = “datasets”) # Information für Paket ‘datasets’
# AirPassengers Monthly Airline Passenger Numbers 1949-1960
# BJsales Sales Data with Leading Indicator
# BOD Biochemical Oxygen Demand
# CO2 Carbon Dioxide Uptake in Grass Plants
# ChickWeight Weight versus age of chicks on different diets
# DNase Elisa assay of DNase
# EuStockMarkets Daily Closing Prices of Major European Stock
# Indices, 1991-1998
# Formaldehyde Determination of Formaldehyde
# HairEyeColor Hair and Eye Color of Statistics Students
# Harman23.cor Harman Example 2.3
# Harman74.cor Harman Example 7.4
# Indometh Pharmacokinetics of Indomethacin
# InsectSprays Effectiveness of Insect Sprays
# JohnsonJohnson Quarterly Earnings per Johnson & Johnson Share
# LakeHuron Level of Lake Huron 1875-1972
# LifeCycleSavings Intercountry Life-Cycle Savings Data
# Loblolly Growth of Loblolly pine trees
# Nile Flow of the River Nile
# Orange Growth of Orange Trees
# OrchardSprays Potency of Orchard Sprays
# PlantGrowth Results from an Experiment on Plant Growth
# Puromycin Reaction Velocity of an Enzymatic Reaction
# Theoph Pharmacokinetics of Theophylline
# Titanic Survival of passengers on the Titanic
# ToothGrowth The Effect of Vitamin C on Tooth Growth in Guinea Pigs
# UCBAdmissions Student Admissions at UC Berkeley
# UKDriverDeaths Road Casualties in Great Britain 1969-84
# UKLungDeaths Monthly Deaths from Lung Diseases in the UK
# UKgas UK Quarterly Gas Consumption
# USAccDeaths Accidental Deaths in the US 1973-1978
# USArrests Violent Crime Rates by US State
# USJudgeRatings Lawyers’ Ratings of State Judges in the US
# Superior Court
# USPersonalExpenditure Personal Expenditure Data
# VADeaths Death Rates in Virginia (1940)
# WWWusage Internet Usage per Minute
# WorldPhones The World’s Telephones
# ability.cov Ability and Intelligence Tests
# airmiles Passenger Miles on Commercial US Airlines, 1937-1960
# airquality New York Air Quality Measurements
# anscombe Anscombe’s Quartet of ‘Identical’ Simple Linear
# Regressions
# attenu The Joyner-Boore Attenuation Data
# attitude The Chatterjee-Price Attitude Data
# austres Quarterly Time Series of the Number of
# Australian Residents
# beavers Body Temperature Series of Two Beavers
# cars Speed and Stopping Distances of Cars
# chickwts Chicken Weights by Feed Type
# co2 Mauna Loa Atmospheric CO2 Concentration
# crimtab Student’s 3000 Criminals Data
# datasets-package The R Datasets Package
# discoveries Yearly Numbers of Important Discoveries
# esoph Smoking, Alcohol and (O)esophageal Cancer
# euro Conversion Rates of Euro Currencies
# eurodist Distances Between European Cities and Between
# US Cities
# faithful Old Faithful Geyser Data
# freeny Freeny’s Revenue Data
# infert Infertility after Spontaneous and Induced
# Abortion
# iris Edgar Anderson’s Iris Data
# islands Areas of the World’s Major Landmasses
# lh Luteinizing Hormone in Blood Samples
# longley Longley’s Economic Regression Data
# lynx Annual Canadian Lynx trappings 1821-1934
# morley Michelson Speed of Light Data
# mtcars Motor Trend Car Road Tests
# nhtemp Average Yearly Temperatures in New Haven
# nottem Average Monthly Temperatures at Nottingham, 1920-1939
# npk Classical N, P, K Factorial Experiment
# occupationalStatus Occupational Status of Fathers and their Sons
# precip Annual Precipitation in US Cities
# presidents Quarterly Approval Ratings of US Presidents
# pressure Vapor Pressure of Mercury as a Function of Temperature
# quakes Locations of Earthquakes off Fiji
# randu Random Numbers from Congruential Generator RANDU
# rivers Lengths of Major North American Rivers
# rock Measurements on Petroleum Rock Samples
# sleep Student’s Sleep Data
# stackloss Brownlee’s Stack Loss Plant Data
# state US State Facts and Figures
# sunspot.month Monthly Sunspot Data, from 1749 to “Present”
# sunspot.year Yearly Sunspot Data, 1700-1988
# sunspots Monthly Sunspot Numbers, 1749-1983
# swiss Swiss Fertility and Socioeconomic Indicators
# (1888) Data
# treering Yearly Treering Data, -6000-1979
# trees Diameter, Height and Volume for Black Cherry
# Trees
# uspop Populations Recorded by the US Census
# volcano Topographic Information on Auckland’s Maunga
# Whau Volcano
# warpbreaks The Number of Breaks in Yarn during Weaving
# women Average Heights and Weights for American Women
# Martin Stoppacher #
# office@martinstoppacher.com #
# – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – – #
#################################################################################